
Nous vivons dans un monde où la sémantique est devenue omniprésente, que ce soit dans les accessoires pour la domotique, les interfaces homme machine (IHM) ou encore dans les systèmes de traduction automatisés. Même les moteurs de recherche comme Google ou le frenchie Exalead surfent sur la vague. Le dernier algorithme de Google, Hummingbird, s’insère doucement mais sûrement dans les résultats de recherche :
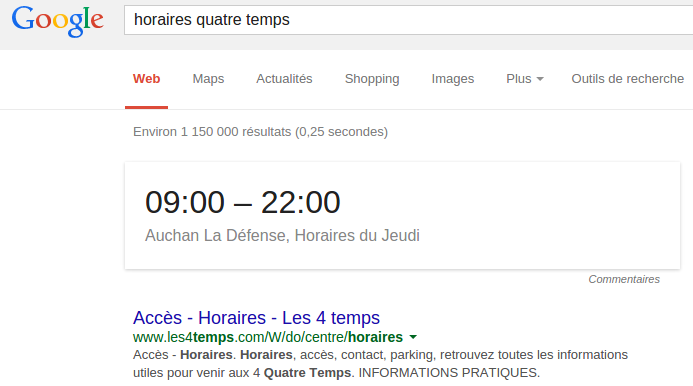
Ces prouesses techniques sont possibles grâce à l’utilisation massive de données sémantiques dans les algorithmes de calcul des pages de résultats. Ces données font intervenir des notions de concepts et de liens qui les unissent. Ce n’est pas clair ? Très bien, prenons pour exemple l’acteur John Wayne et allons faire un tour sur Freebase, la base de données encyclopédique de Google :
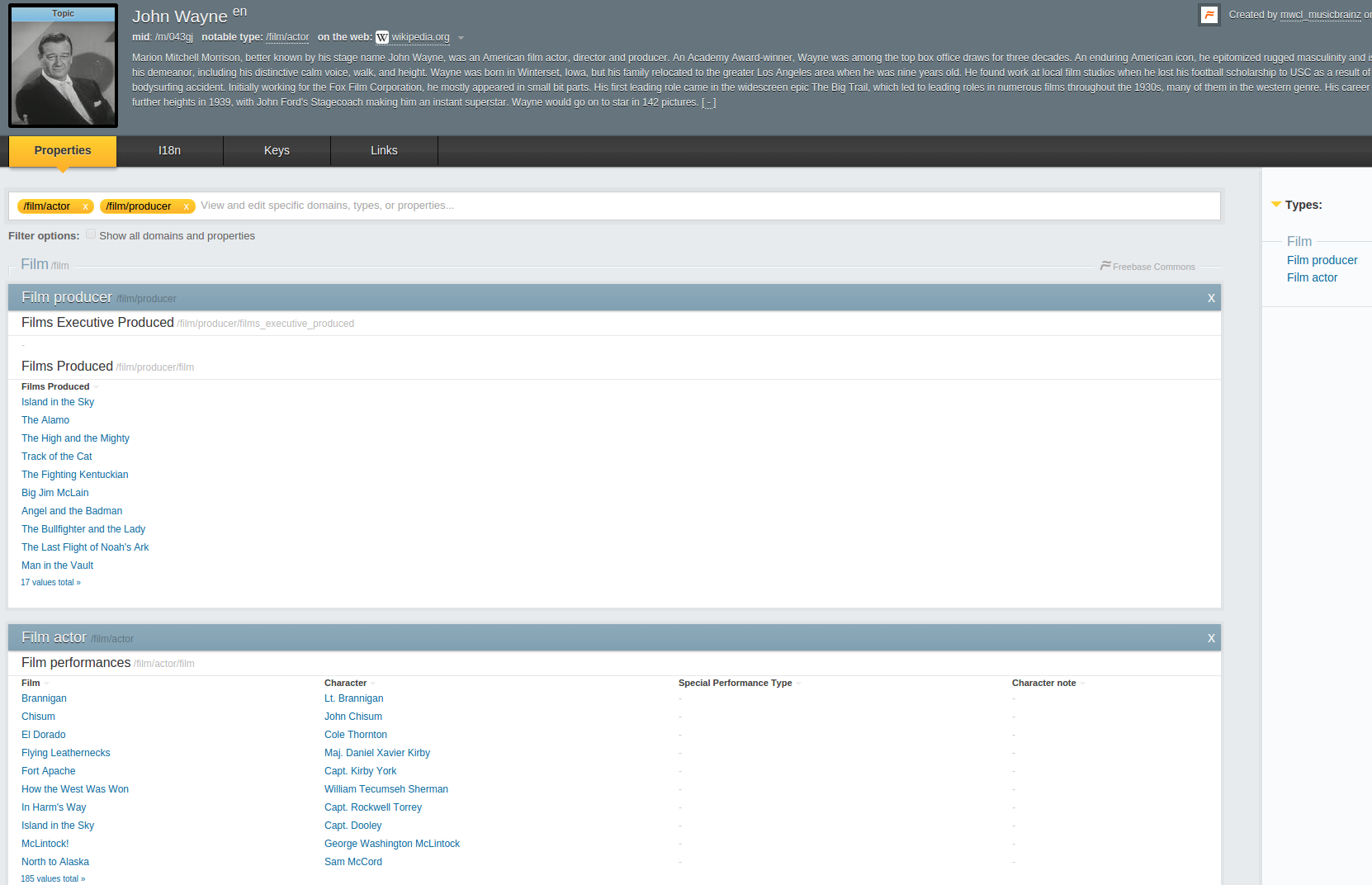
Dans cet exemple, l’entité John Wayne est associée à de multiples concepts. Elle est reliée, entre autres, à Brannigan et El Dorado dans le cadre d’une relation nommée Film Actor, et à Island in the Sky dans une relation Film Producer. Ces relations sont les propriétés des concepts. On peut représenter les concepts et leurs propriétés à travers un graphe, qu’on appelle alors Ontologie :
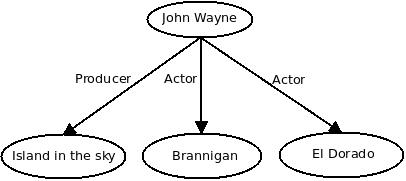
Avec des ontologies plus complètes comme celles de Freebase ou Wikipedia (via la base ouverte DBPedia), on peut facilement extraire la liste des acteurs américains ayant joué dans au moins un des films avec John Wayne… Intéressant pour un moteur de recherche !
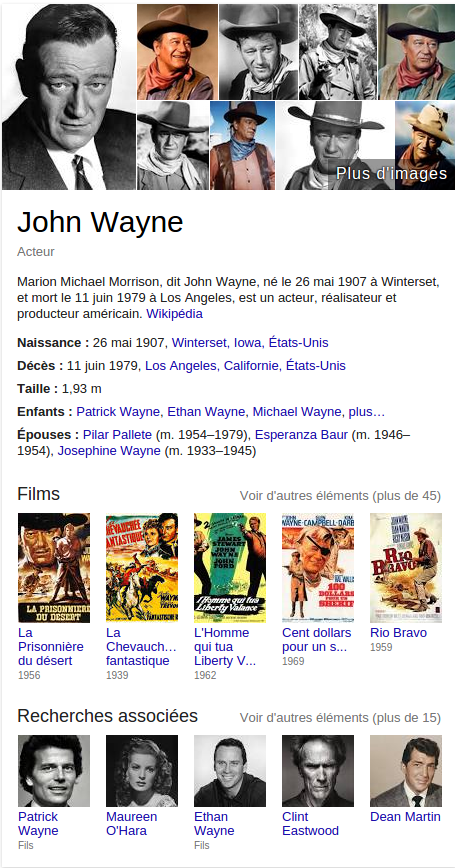
Les algorithmes de Google sont capables de calculer automatiquement des graphes de concepts à partir d’une page quelconque grâce à la quantité gigantesque de données sémantiques présentes sur les pages qu’il a déjà crawlées et de multiples ressources linguistiques. Les erreurs algorithmiques n’étant pas rares (même pour Google !) et la correction humaine très coûteuse, il existe un moyen d’aider les moteurs à comprendre une page de votre site afin qu’il génère un graphe conceptuel logique.
Cela s’appelle les microdonnées (ou microdata en anglais).
Le concept derrière les microdonnées
Les microdonnées sont des données structurées codées directement dans le code HTML qui permettent d’identifier un concept au sein de la page et de décrire ce concept au sein d’une structure précise de propriétés attributs/valeurs. Il existe plusieurs systèmes de microdonnées, FOAF, Schema.org ou encore Microformat pour ne citer qu’eux. On peut également préciser que les microdonnées ont été pensées bien avant l’arrivée du langage HTML5, et ne sont donc pas directement liées à l’évolution du HTML même si elles y participent activement.
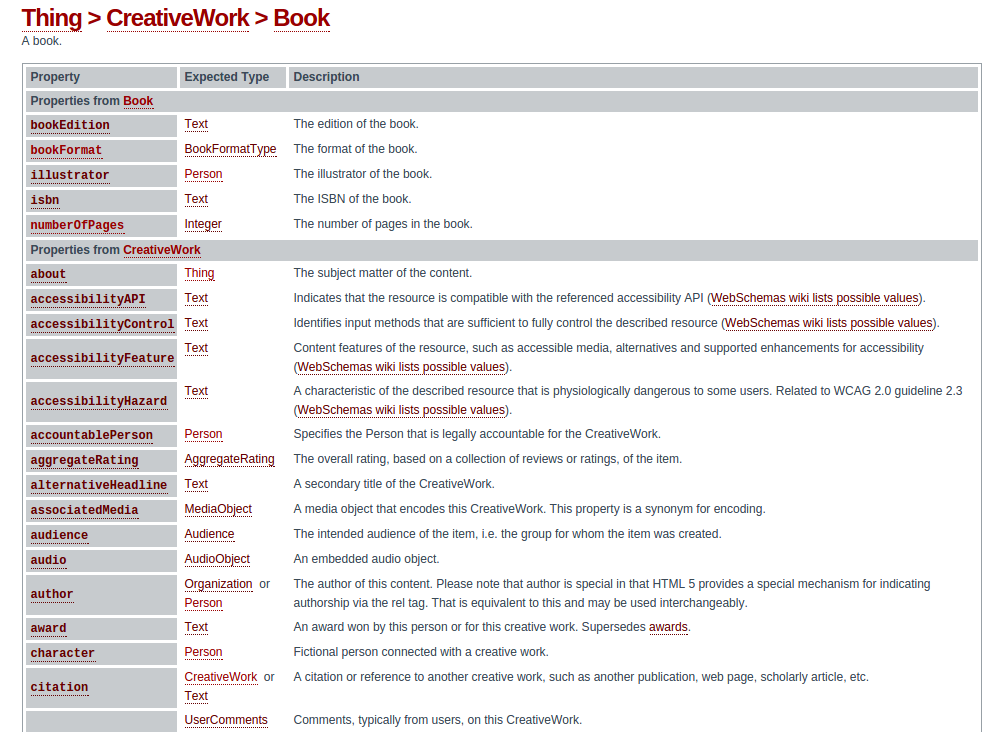
Il faut noter que Schema.org est devenu le standard de structuration des microdonnées après une concertation en 2011 des quatres grands représentants du monde des moteurs de recherche : Bing, Google, Yahoo et Yandex. Schema.org est une hiérarchie assez complexe de meta-concepts et contient un nombre important de sous-niveaux. Pour le super-concept « CreativeWork », on peut par exemple trouver des sous-concepts « Book », « Article », « Movie »,… Tout le monde peut y trouver son compte quel que soit son domaine d’activité !

En regardant de plus près la classe Book, vous pouvez voir la (longue) liste des propriétés qui permettent de décrire un livre présent sur votre page. Cela va du classique auteur, jusqu’aux personnages présents dans le livre, en passant par les mots clés. Evidemment la plupart de ces propriétés ont un caractère optionnel, mais retenez bien que plus c’est complet plus les moteurs apprécient.
Le concept derrière les microdonnées
Nous avons parlé de l’utilité des microdonnées mais pas de leur représentation au sein du code HTML. Il faut utiliser une structure bien définie permettant d’encapsuler nos données. Vous vous en doutez il existe plusieurs formats et donc plusieurs syntaxes d’écriture : Microdata, RDFa ou encore JSON-LD sont les plus connus et les plus utilisés. Ci-dessous, un exemple d’annotation d’un code HTML avec des microdonnées Schema.org selon ces trois formats (extrait de Wikipedia) :
Microdata
<div itemscope itemtype="http://schema.org/Movie">
<h1 itemprop="name">Avatar</h1>
<div itemprop="director" itemscope itemtype="http://schema.org/Person">
Director: <span itemprop="name">James Cameron</span>
(born <time itemprop="birthDate" datetime="1954-08-16">August 16, 1954</time>)
</div>
<span itemprop="genre">Science fiction</span>
<a href="../movies/avatar-theatrical-trailer.html" itemprop="trailer">Trailer</a>
</div>RDFa
<div vocab="http://schema.org/" typeof="Movie">
<h1 property="name">Avatar</h1>
<div property="director" typeof="Person">
Director: <span property="name">James Cameron</span>
(born <time property="birthDate" datetime="1954-08-16">August 16, 1954</time>)
</div>
<span property="genre">Science fiction</span>
<a href="../movies/avatar-theatrical-trailer.html" property="trailer">Trailer</a>
</div>JSON-LD
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "Movie",
"name": "Avatar",
"director":
{
"@type": "Person",
"name": "James Cameron",
"birthDate": "1954-08-16"
},
"genre": "Science fiction",
"trailer": "../movies/avatar-theatrical-trailer.html"
}
</script>
Microdata et RDFa fonctionnent de manière similaire. Les microdonnées sont codées dans des attributs HTML au niveau des balises existantes du code source. Avec Microdata, par exemple, les attributs itemscope et itemtype permettent de déclarer la création d’un nouveau concept au sein de la page et d’associer ce concept à un meta-concept d’une ontologie, ici http://schema.org/Movie. Quant à l’attribut itemprop, il permet d’associer une propriété au concept en cours.
JSON-LD fonctionne totalement différemment. Comme vous pouvez le voir, les concepts sont déclarés non plus au sein du code HTML, mais dans une structure particulière contenue dans du code Javascript. JSON-LD est un format relativement récent, contrairement à RDFa et Microdata, mais est devenu la nouvelle norme imposée par W3C.
JSON-LD, kezako ?
Il faut tout d’abord noter que JSON-LD dérive du format JSON, le format d’échange de données par défaut du langage Javascript. Il permet de déclarer des structures clé/valeur, structures particulièrement intéressantes lorsqu’on veut définir des concepts… Dans le cadre de JSON-LD, les clés sont les propriétés du concept, associées à leur valeur. Les valeurs peuvent être des références à d’autres concepts, des nombres ou encore du texte simple.
Les propriétés @context et @type sont obligatoires et permettent de définir respectivement l’ontologie utilisée et le meta-concept du concept courant. Les autres propriétés dépendent du meta-concept. Si on définit une personne, il est logique de définir les propriétés name, birthDate ou encore nationality. Vous pouvez voir la liste complète des propriétés pour la classe Person ici : http://schema.org/Person.
Si nous devions créer la structure JSON-LD pour notre exemple initial, John Wayne acteur dans Brannigan, elle ressemblerait à celle-ci :
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "Movie",
"name": "Brannigan",
"genre": "Thriller",
"trailer": "https://www.youtube.com/watch?v=gAhzli9jbKU",
"actors":
{
"@type": "Person",
"name": "John Wayne",
"birthDate": "1907-05-26"
}
}
</script>
Il est tout à fait possible d’imbriquer des structures JSON-LD. Dans le cas présent, on définit un nouveau concept John Wayne à l’intérieur même de la déclaration du film à travers la propriété actors. Ci-dessous, un autre exemple de structure JSON-LD imbriquée décrivant deux concepts, une personne et son adresse postale :
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Person",
"name": "John Doe",
"jobTitle": "Graduate research assistant",
"affiliation": "University of Dreams",
"additionalName": "Johnny",
"url": "http://www.example.com",
"address": {
"@type": "PostalAddress",
"streetAddress": "1234 Peach Drive",
"addressLocality": "Wonderland",
"addressRegion": "Georgia"
}
}
</script>
Pourquoi JSON-LD devient la nouvelle norme ?
L’intérêt majeur de JSON-LD repose dans l’interaction qu’il peut avoir avec les bases de données, principalement NoSQL. A l’heure du Big Data, tous les grands groupes actifs sur internet migrent doucement vers le paradigme NoSQL pour des raisons de rapidité. Google utilise sa solution BigTable, Amazon avec DynamoDB ou Twitter avec Cassandra.

Or, la plupart de ces groupes mettent à disposition des API permettant d’interroger leurs bases ou d’envoyer des données vers celles-ci. Il s’agit généralement d’API Rest qui sont des services accessibles à travers le protocole HTTP. Le format d’échange des messages par défaut de ces API est JSON, pour plusieurs raisons : la facilité de compréhension, la structuration et le faible poids. Il est donc (théoriquement) très simple pour ces grands groupes d’ajouter une couche sémantique avec JSON-LD, si ce n’est pas déjà fait.
Déjà reconnu par Google
Autre point positif pour un administrateur de site : si le code HTML change en terme de structure, les microdonnées JSON-LD ne sont pas impactées car indépendantes des balises HTML. La maintenance s’en trouve grandement aisée. Ce type de microdonnées est déjà reconnu par Google, au moins dans son outil de validation des données structurées : plus besoin de l’intégrer à votre page web, une simple déclaration dans le header HTML suffit.
JSON-LD pourrait bien être l’avenir du web sémantique. Être bien intégré à un univers sémantique pourrait devenir aussi important que d’avoir des bons backlinks Et vous, avez-vous déjà mis en place du JSON-LD sur vos sites?

